
hey大家好,
写作课最后一个作业了,做一些数据分析,翻译腔还在持续,太尴尬了,建议朋友们还是直接读英文版吧 😅 如果有nlp方面的专业人士希望多多给我的数据分析过程一些建议!
英文版在:https://chenshuz.substack.com/p/finding-top-10-matches-from-100-essays
写作的小确幸
十月份我参加了一个写作课,这次经历完全超出了我的预期。没想到跟别人聊天能成为写作过程的重要组成部分。以前,我从想法到发布都是自己闭门造车,但在课程中,每个阶段都我都和其他学生互动,从理清想法、收集草稿反馈到分享作品。
这些互动带来了许多意外之喜。在写作聊天室里,我不止一次发现随机分到的课友在写和我相似的想法。还有人会在我的文章下留言,说他们也经历过同样的心路历程。这些跨越地理位置、种族或人生阶段的共同想法和经历让我很惊喜,感到了自己和世界的连接。(当然也可能是我不经常上网,或者太阳底下没有新鲜事)
我不禁想,在我还没遇到课友或是作者里,还有谁和我的想法和写作主题一样?我是否可以主动寻找,而不是依靠随机概率或等待别人偶然发现我的文章?如果我想在 800 名同学中找到和我的文章最有共鸣的前 50 名作者,该怎么办?我如何才能更系统地发现我的写作灵魂伴侣?
实验设计
如果我要从 800 篇文章中手动找出前 50 名写作灵魂伴侣,我必须读完所有 800 篇文章,并评估哪一篇与我的主题相似。这听起来工作量很大,自动化听起来像是完美的选择。想象一下一个像 Google 搜索一样的程序,用我的文章作为关键词查询一个800篇文章的数据库,按最相关到最不相关的顺序对结果进行排序。
当我分享我的想法时,gpt老师说:“你的意思是计算这 800 篇文章的semantic embedding之间的cosine similarity,然后排序并选择前 50 个匹配项?”
是的,我就是这个意思。现在请像 4 岁小孩一样向我解释“semantic embedding”和“cosine similarity”是什么意思。

Semantic Embedding
semantic embedding是由text embedding model 生成的基于vector的文本表示。
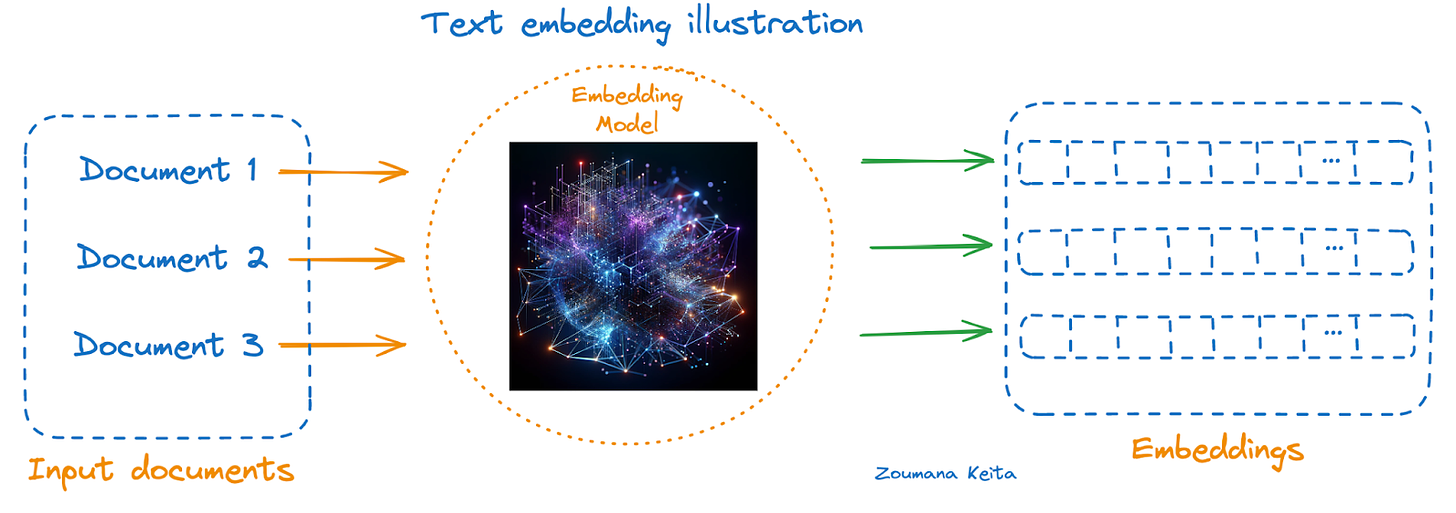
我使用了模型text-embedding-3-small ,这是一个预训练的模型,它可以理解复杂的语言模式和关联,因此可以直接用于相似性搜索、聚类和分类等任务。
将文章作为模型的新输入,它将文本编码为一个向量,包含文本的各个层次的含义,例如主题、情感、意图、上下文、结构等。
Cosine Similarity
具有相似含义的文章在向量空间中会有指向相似方向的向量。Cosine Similarity测量两个向量之间的角度,因此常用于计算两篇文章之间的相似度。
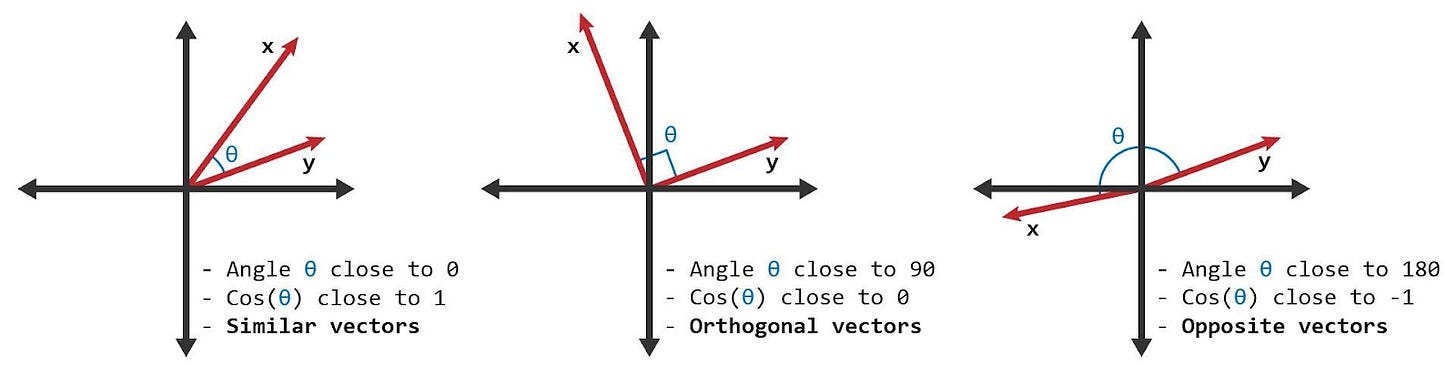
余弦分数范围从 1 到 -1,例如“car”和“automobile”的含义几乎相同,其余弦分数接近 1;而“car”和“banana”不相关,其分数接近 0;“happy”和“sad”的分数为 -1,因为它们的含义相反。
结果
我最终从我的写作课中抓取了 100 篇已发表的文章,将它们转换为semantic embeddings,并使用我自己的文章作为查询来计算每篇文章的cosine similarity。如果你对这个过程感兴趣,由于电子邮件太长,我会在另一篇文章解释细节。
82 个分数的总体分布
对于semantic embedding, cosine similarity 分数通常在 0 到 1 之间。
[1 - 0.8]:高度相关
[0.8 - 0.5]:主题相似,细节不同
[0.5 - 0]:不怎么相关的主题
语义上与我的写作最接近的 10 篇文章
- burning-man-stories-how-to-figure-out-the-unknown : 1.000
- 13-no-i-didnt-travel-on-my-sabbatical : 0.743
- the-mind-bin : 0.701
- death-fatherhood-and-ayahuasca : 0.676
- surf-and-the-art-of-solopreneurship : 0.670
- gn-49-figuring-out-whats-the-plan : 0.668
- how-to-walk-to-a-mens-group : 0.668
- slow-spaces-for-conversation : 0.661
- third-times-the-missing-element-in-our-third-places : 0.659
- the-antidote-to-writers-block-is-friendship : 0.659
- independence-is-overrated : 0.658
- my-lighthouse-to-kindness : 0.653
发现 1:我是我自己的写作灵魂伴侣
在前 10 篇文章中,条目 0 是用来搜索的文章,得分为满分 1。有趣的是,排在第二位的实际上是我自己的另一篇文章!
我的两篇文章结构和主题相似,但细节不同。它们都是英雄之旅结构,专注于通过自我探索摆脱生活中的困境。它们的方法不同。在《火人节》一文中,我从外部世界获得灵感,而在《休假》文章中,我进行了一次内心之旅。两篇文章都得出了相同的结论:我应该做我喜欢的工作,花时间在创造性爱好上,并与他人建立真正的联系。
相似度得分 0.743 感觉很合理,因为它表明我的文章在含义上有很大重叠,但并不完全相同。任何超过 0.85 的相似度都可能意味着抄袭。我最初对这个算法持怀疑态度,但看到我的另一篇文章排名靠前,我就比较相信它的准确性了。
发现2:文章主题相同,但写法不同
我快速阅读了前10 的文章并注意到了反复出现的主题。
前四篇文章的作者都讲了自己人生改变的故事,例如搬到新国家、将重心从事业转移到家庭、辞去公司工作开创自己的公司,或制定退休计划。其中的共同点是渴望真实地生活,即使要付出一些机会成本。
接下来的六篇文章重点关注真诚的人际关系的重要性,例如与陌生人在第三空间聊天,在第三时间聊天,在男性小组中聊天、在作家小组中聊天,或者与朋友和家人聊天。这些场景强调了与人真诚交流和完全做自己所带来的乐趣。
我对这些作家的人生经历和主题关注深有同感。Rick Lewis 文章中的一段话是以上内容的一个很好的总结[2]:
关键在于,当我们的生活和经历违背既定规范时,我们很容易质疑其合法性,然后脱离自我,几乎将自己视为与他人无关的异常现象。
这也许是每个作家的瞬间诞生点。当一个人想到“我没有疯,我只是个凡人”时——他意识到这是值得写的东西。
除了共鸣之外,我发现每个人在探讨类似的想法时都会有自己独特的声音。例如,在表达“生活不可预测”这一想法时,我就没想到还能这样说:
宇宙是一列载满实验的火车,无论我们在轨道上投入多少思想,我们都永远无法减慢它的速度或让它脱轨。the universe is a freight-train of experimentation that we’ll never be able to slow down or derail, no matter how many pennies of thought we place on its tracks. [2]
发现 3:排名最后的10 篇文章
72: the-death-of-serendipity : 0.487
73: micro-moments-a-stepfathers-guide-to-invisible-love : 0.477
74: 9-to-5-perimenopausal-progress : 0.462
75: toxic-humility : 0.458
76: a-sharp-knife-is-all-i-need : 0.450
77: food-doesnt-taste-better-with-friends : 0.433
78: empty-calorie-innovation-is-a-bad : 0.428
79: if-you-want-it : 0.423
80: what-can-we-learn-from-a-race-car-driver-about-business: 0.419
81: product-managers-should-remember : 0.386
82: influencer-marketing-is-emerging : 0.346
为了公平起见,我们也应该看一下排名垫底的10篇文章。
排名最后的 5 篇文章更具代表性,因为它们都侧重于商业、金融或营销领域。第 5 至第 10 篇文章涵盖了更广泛的主题,如文化、媒体和妇女权利等,而这些主题我很少在自己的写作中谈论。我可能应该考虑将这些主题添加到我的阅读清单中。
算法排名最低的10篇文章,更多的是“不相关”的类别,而不是“相反”的类别。不过,开发一个专门用于查找观点相反的文章的程序可能也会很有用。
下一步
用人工智能告诉我为什么两篇文章在哪些方面相似
AI 给出的结果就像一个黑箱,我一直在想它为什么会选择这些文章,我希望它能给我解释两篇文章到底哪些方面相似。
为了看看黑箱是怎么工作的,我可以做一些辅助分析
- 要求 GPT 解释结果并通过reverse engineering重复该过程
- 使用主题建模 (LDA) 或关键词 (TF-IDF) 等技术来识别相似主题
- 使用层次分析来识别相似的结构
我打算继续我的探索,并将解释部分自动化。如果你感兴趣,请点击订阅持续关注这项工作的进度。
将用途扩展到所有 Substack 文章
博客/时事通讯平台可以将其用于推荐系统,这样当您发布一篇文章时,您就可以获得具有相似(或相反😂)含义的文章列表。
Substack 已经采用了类似的功能;当你发布一条笔记时,它会推荐一系列相关的笔记。
参考
- Zoumana Keita 的插图: https: //www.datacamp.com/tutorial/exploring-text-embedding-3-large-new-openai-embeddings
- 我在文章中多次引用了 Rick 的精彩文章:友谊是解决写作障碍的良药
Member discussion: